
최근 AMD RDNA 기반 플랫폼의 최적화 작업을 하면서 RNDA 아키텍처와 관련된 여러 최적화 자료를 찾아보았다.
그 중에서 RNDA 기반은 아니지만 AMD GCN 아키텍처 GPU와 관련된 좋은 리소스가 있어서 번역을 해봐야겠다는 생각을 하였다.
이 글은 Optimizing GPU occupancy and resource usage with large thread groups을 번역한 글입니다.
많은 의역이 있으니 참고바랍니다.
큰 사이즈의 스레드 그룹을 통한 Occupancy, 리소스 사용 최적화
(각주 : Occupancy가 무엇인지 모른다면 이 글을 참고하시길 바랍니다)
컴퓨트 쉐이더를 사용할 때, 스레드 그룹의 사이즈가 성능에 주는 영향을 고려하는 것이 중요합니다. 제한된 레지스터 공간, 메모리 레이턴시, SIMD occupancy 각각은 여러 측면에서 쉐이더 성능에 영향을 줍니다. 이 글은 잠재적인 성능 문제를 알아볼 것이고, 올바르게 적용된다면 드라마틱하게 성능을 향상시킬 수 있는 최적화/기술들에 알아볼 것입니다. 이 글은 큰 사이즈의 스레드 그룹과 관련된 문제에 대해 집중적으로 다룰 것이지만, 이 글에서 소개될 여러 팁/트릭들은 다른 사례들에도 공통적으로 적용될 수 있는 것들입니다.
배경 지식 D3D11 쉐이더 모델 5 컴퓨트 쉐이더 스펙은 스레드 그룹당 허용되는 최대 메모리 사이즈를 32KB로 제한하고, 최대 Workgroup 사이즈를 1024 스레드로 제한합니다. 최대 레지스터 개수에는 딱히 제한은 없지만, 레지스터의 공간이 한정적이기 떄문에 필요하다면 컴파일러는 레지스터의 데이터를 메모리로 옮길 것입니다(각주 : spill하다 -> 레지스터의 데이터를 느린 메모리로 옮긴다). 그러나 메모리 레이턴시 때문에(각주 : 앞에서 설명했듯, 메모리는 레지스터에 비해 레이턴시가 좋지 않다), Spilling은 심각하게 성능을 저하시키므로, 실제 프로덕션 코드에서는 반드시 피해야합니다.
현대 AMD GPU는 단일 컴퓨트 유닛(CU)에서 1024개의 스레드들로 구성된 두 개의 그룹을 동시에 실행시킬 수 있습니다. 그러나, Occupancy를 최대한 높이기 위해 쉐이더는 레지스터와 LDS 사용을 최소화해야합니다. 그래야만 모든 스레드들로부터 요구되는 리소스가 CU에 딱 들어맞기 때문입니다.
AMD GCN 컴퓨트 유닛(CU)
GCN 컴퓨트 유닛(CU)의 아키텍처를 살펴봅시다.
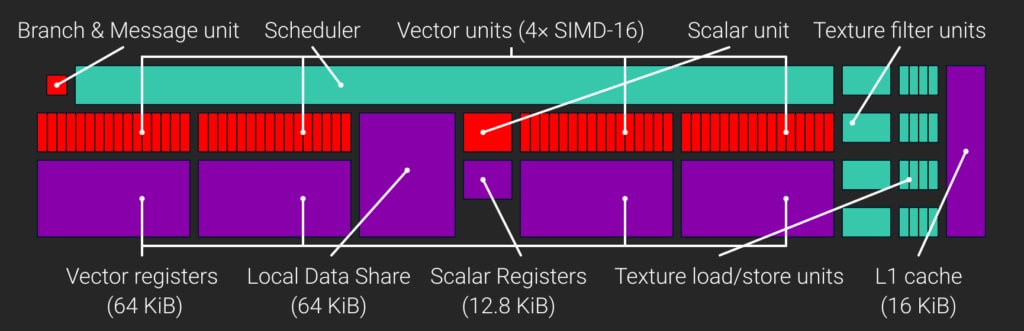
GCN CU는 4개의 SIMD를 가지고 있고, 각각의 SIMD는 32bit VGPRs(Vector General-Purpose Register)의 64KB 레지스터 파일을 가지고 있습니다. 그래서 CU당 총 65,536 VGPRs입니다. 또한 모든 CU는 32bit SGPRs(Scalar General-Purpose Registers) 레지스터 파일을 하나 가지고 있습니다. (각주 : VGPR과 SGPR에 대해 잘 모르신다면, 이 글을 참고하시기 바랍니다.) GCN3까지는, 각각의 CU는 512개의 SGPR을 가지고 있었고, GCN3부터는 800개로 늘어났다. 이는 CU당 총 3200개의 SGPR(12.5KB)을 가지고 있다는 것을 의미한다.
CU가 실행하는 스케줄된 작업의 가장 작은 유닛을 “Wave”라고 부른다.(각주 : NVIDIA에서는 “Wave”가 아닌 “Warp”라는 용어를 사용한다) 그리고 각각의 Wave는 64개의 스레드로 구성되어 있다. CU의 4개의 SIMD 각각은 최대 10개까지 Wave를 동시에 스케줄할 수 있다.(각주 : 10개의 Wave를 동시에 실행한다는 의미는 아니고… 10개의 Wave를 대기시켜두고 어떤 이유로 Stall이 발생하면 다른 Wave를 동작시키는 방식으로 동작한다. 자세한건 이 글을 참고하길 바란다.) CU는 한 Wave를 실행하다 메모리 연산(메모리 읽기/쓰기)을 수행하여 Stall되는 경우 해당 Wave를 중지시키고 다른 Wave를 실행시킬 수 있다. 이러한 동작은 CU의 컴퓨터 리소스를 최대한 활용하고, 레이턴시를 숨기는데 도움을 준다.
SIMD VGPR 파일들의 사이즈는 중요한 한계가 있는데, SIMD의 VGPR 개수는 Active한 Wave(각주 : 이 글에 잘 소개되어 있는데, SIMD는 메모리 Stall등의 상황에 대비하여 여러 Wave들을 대기시켜둔다. 이렇게 대기시켜둔 Wave들을 Active한 Wave라고 말한다)들의 스레드들에 공평하게 나누어진다는 것이다. 만약 쉐이더가 SIMD가 가진 VGPR보다 더 많은 VGPR을 요구한다면, 최적의 개수만큼의 Wave를 실행할 수 없을 것이다. Occupancy, 즉 어떤 시점에 GPU가 수행할 수 있는 병력 작업의 척도는 결과적으로 나빠질 것이다.
각각의 GCN CU는 64KB의 Local Data Share(LDS)를 가지고 있다. LDS는 컴퓨트 쉐이더 스레드 그룹들의 groupshared 데이터를 저장하는데 사용된다.(각주 : 언리얼 엔진의 컴퓨트 쉐이더들을 보시면 종종 “groupshared”라는 키워드를 발견하실 수 있을겁니다.) Direct3D는 groupshared 데이터의 양을 단일 스레드 그룹당 32KB까지만 사용할 수 있도록 제한해두었다. 그러므러 우리는 LDS를 최대한 활용하기 위해, 각 CU당 최소한 2개의 그룹들 동작시켜야합니다.
큰 사이즈의 스레드 그룹 리소스 목표
이 글에서 예제로 나오는 쉐이더는 1024개의 사이즈로 구성된 스레드 그룹을 가진 복잡한 GPGPU 피직스 솔버 쉐이더이다. 이 쉐이더는 최대 사이즈의 그룹 사이즈를 사용하고, groupshared 메모리의 최대 한도까지 사용한다. 이 쉐이더는 groupshared 메모리를 여러 패스들 사이에 임시 저장소로 사용함으로서 물리 처리 제약을 해결하였기 떄문에, 큰 그룹 사이즈의 혜택을 본다. 스레드 그룹 사이즈가 더 크다는 것은 글로벌 메모리에 중간(임시) 결과를 쓸 필요 없이, 더 큰 섬(?)을 처리할 수 있다는 것을 의미한다.(각주 : 더 큰 섬을 처리할 수 있다 -> 더 많은 물리양의 처리를 수행할 수 있다)
1024개의 스레드의 그룹을 효율적으로 처리하기 위해 달성해야할 리소스 목표들에 대해 얘기해봅시다.
레지스터 : GPU를 바쁘게 굴리기 위해, 각각의 CU는 1024개의 스레드로 구성된 그룹 두개를 배정받아야합니다. 전체 CU에 대해 이용 가능한 VGPR이 65,536개라는점에서, 각 스레드는 한번에 최대 32개의 VGPR을 요구할 것입니다.
Groupshared 메모리 : GCN는 64KB의 LDS를 가지고 있스빈다. 그리고 우리는 groupshared 메모리 32KB를 완전히 사용할 수 있고(각주 : 위에서 말했듯이 Direct3D가 스레드 그룹당 groupshared 메모리르 32KB까지만 사용할 수 있도록 제한해두었기 때문에), CU당 2개의 그룹을 배정할 수 있습니다.
만약 쉐이더가 이 제한을 넘어간다면, CU에 2개의 그룹을 동시에 실행시킬 수 없게됩니다. 32개의 VGPR이라는 목표는 달성하기가 까다롭습니다. 일단 우리는 먼저 이 목표를 달성하지 못하였을 때 직면하게 되는 문제들에 대해 얘기를 해볼 것이고, 이 문제를 해결하기 위한 해결책, 마지막으로는 어떻게 그것을 피할 수 있는지를 알아볼 것입니다.
문제점 : CU당 오직 하나의 스레드 그룹
프로그램이 스레드 그룹 사이즈 최대 제한한도(1024개)까지 사용하지만, 쉐이더는 40개의 VGPR을 요구하는 경우를 가정해봅시다. 이 경우 CU당 오직 하나의 스레드 그룹만이 실행될 것입니다. 쉐이더가 40개의 VGPR을 요구하는 경우, 2048개의 스레드, 즉 2개의 스레드 그룹을 동작시키데 81,920개의 VGPR을 요구합니다. 이는 CU에 이용 가능한 65,536개를 훨씬 뛰어넘는 숫자입니다.
1024개의 스레드는 64개의 스레드로 구성된 Wave 16개를 생성할 것입니다. 그리고 이는 SIMD들에 공평하게 분배되어, SIMD당 4개의 Wave를 가지게됩니다. 우리는 앞서 배웠듯이 최적의 Occupancy, 레이턴시 숨김은 10개의 Wave를 요구합니다. 그래서 4개의 Wave는 결과적으로 40%의 Occupancy만을 가지게합니다. 이는 GPU가 레이턴시를 숨겨줄 가능성을 줄이고, 결과적으로 낮은 SIMD 사용율(로드율)을 유발합니다.(각주 : 레이턴시로 인해 GPU가 논다)
102개의 스레드로 구성된 스레드 그룹이 32KB의 LDS를 완전히 활용한다고 생각해봅시다. 레지스터 압박 때문에(각주 : VGPR 부족으로) 스레드 그룹이 하나만 동작하기 때문에, 그 하나의 그룹이 동작할 때 다른 스레드 그룹을 위해 존재하는 나머지 절반의 LDS 공간은 활용되지 못하게 됩니다. 스레드당 40개의 VGPR, 총 40,960 VGPRs, 즉 레지스터 파일 사용은 160KB에 불가합니다. 즉 각 CU당 레지스터 파일의 96KB(37.5%)가 낭비되고 있다는 말입니다.
만약 VGPR 예산을 초과하여, 하나의 CU에 오직 하나의 스레드 그룹만을 배정할 수 있다면, 최대 그룹 사이즈는 나쁜 GPU 리소스 로드율을 초래하게 되는 것을 알 수 있습니다.
잠재적인 그룹 사이즈 구성을 계산할 때, GPU 리소스 라이프사이클을 고려하는 것이 중요합니다.
GPU는 한 스레드 그룹에 필요한 모든 리소스를 동시에 할당하고, 해제합니다. 레지스터, LDS 그리고 Wave 슬롯들은 그룹이 동작을 시작하기 전 모두 할당되고, 그룹의 마지막 Wave가 동작을 마쳤을 때, 모든 리소스를 한번에 해제됩니다. 그래서 오직 하나의 스레드 그룹만이 CU에 들어간다면, 각각의 그룹이 동작을 시작하기 전 이전 그룹이 끝나기를 기다려야하기 때문에, 할당/해제에서 Overlap이 없어지게 됩니다.(각주 : CU에 두 개의 스레드 그룹을 배정하는 경우 두 스레드 그룹이 CU에서 리소스를 Overlap해서 할당/해제하나보니다.) 메모리 레이턴시를 예측할 수 없기 떄문에, 그룹 내의 Wave들은 각기 다른 시간에 동작을 끝마치게 될 것입니다. 이전 그룹의 모든 Wave들이 동작을 끝마칠 때까지 다음 그룹의 Wave들은 동작을 시작할 수 없기 떄문에 Occupancy는 감소합니다.
큰 스레드 그룹은 LDS를 많이 사용하는 경향이 있습니다. LDS 접근는 barriers(“GroupMemoryBarrierWithGroupSync”, link, in HLSL)을 통해 동기화됩니다. 각각의 barrier은 같은 그룹에 속한 다른 Wave들이 모두 그 barrier에 도착할 때까지 Wave의 동작을 중단시킵니다. 이상적으로 CU는 한 그룹이 barrier에서 대기 중인 동안, 다른 스레드 그룹을 실행할 수 있습니다.
불행히도, 우리 예제에서 우리는 오직 하나의 스레드 그룹만을 실행하고 있습니다. 오직 하나의 그룹이 CU에서 동작할 때, barrier는 모든 wave들을 쉐이더 명령어의 동일한 한정된 세트들로 제한합니다. 그러한 명령어 세트는 대개 두 barrier 사이에서 단조로우므로, 한 스레드 그룹 내의 모든 wave들은 메모리를 동시에 로드할 가능성이 높습니다. 그 barrier가 쉐이더의 이후 독립된 부분으로 넘어가는 것을 막기 때문에, 메모리 레이턴시를 숨겨줄 수 있는 유용한 ALU 동작을 위해 CU를 사용할 수도 없을겁니다.
해결책 : CU당 두 개의 스레드 그룹
CU당 두개의 스레드 그룹을 가지는 것은 이러한 문제점들을 상당히 줄여줍니다. 두 그룹은 다른 시간에 끝나고, 다른 시간에 barrier에 다다를 가능성이 높습니다. 그리고 이는 명령어 혼합을 늘려주고, Occupancy 감소 문제를 상당히 줄여줍니다. 결과적으로 SIMD 로드율은 더 높아지고, 더 많은 레이턴시 숨김의 기회가 생깁니다.
나는 최근 1024개의 스레드 그룹 쉐이더를 최적화하였습니다. 원래 그 쉐이더는 48개의 VGPR을 사용했었는데, 이는 CU당 오직 하나의 그룹만을 동작할 수 있는 개수입니다. VGPR 사용을 32개까지 줄임으로서 어떠한 다른 최적화도 없이 한 플랫폼에서는 50%의 성능 향상을 이룰 수 있었습니다.
CU당 두 개의 그룹은 최대 사이즈의 스레드 그룹을 사용할 때 아주 적합합니다. 그러나, 심지어 두 개의 그룹으로도 Occupancy 출렁임은 완전히 제거되지 않습니다. 큰 스레드 그룹 사이즈를 사용하기로 결정하기 전, 그로 인해 얻어지는 이득과 손해를 분석하는 것이 중요합니다.
언제 큰 스레드 그룹이 사용되어야 하는가
문제를 해결하는 가장 쉬운 방법은 그 문제를 완전히 피하는 것입니다. 위에서 언급했던 문제들 대다수는 더 작은 스레드 그룹을 사용함으로서 해결할 수 있습니다. 만약 너의 쉐이더가 LDS를 요구하지 않는다면, 더 큰 스레드 그룹을 사용할 필요는 전혀 없습니다.
LDS가 필요하지 않을 때, 너는 64개에서 256개의 정도의 스레드 개수를 선택하는 것이 좋습니다. AMD는 기본적으로 256개의 스레드 그룹을 추천하는데, 이는 이 개수가 AMD의 작업 분배 알고리즘에 적합하기 떄문입니다. 하나의 Wave, 즉 스레드 그룹 사이즈를 64개로 선택한 경우 또한 쓰임새가 있습니다. 그 wave가 끝나자마자 GPU는 리소스를 해제할 수 있고, AMD 쉐이더 컴파일러는 모든 wave가 lock step으로 진행될 것이 보장되기 때문에, 모든 메모리 barrier를 제거할 수 있습니다. Sphere Tracing 알고리즘과 같이 변동성이 심한 루프를 가진 작업(for문의 루프 횟수가 일정치 않고 매번 다른)의 경우 단일 wave work 그룹으로부터 가장 많은 이득을 볼 수 있습니다.
그러나, LDS는 다른 쉐이더 단계에는 없는 컴퓨트 쉐이더만의 매력적이고, 유용한 기능이기 떄문에, 그것을 적절히 사용했을 때 큰 성능 향상을 가져다줍니다. 각 스레드들이 모두 동일한 값을 가지느 공통 데이터를 각 스레드가 매번 별도로 로드하기 보다, 공통 데이터를 LDS로 한번만 로드함으로서 불필요한 메모리 접근을 줄일 수 있습니다. 효율적인 LDS 사용은 L1 캐시 미스율, 캐시 thrashing 문제를 줄여주고, 그에 상응하는 메모리 레이턴시, 파이프라인 Stall도 줄여줄 것입니다.
스레드 그룹 사이즈를 줄였을 때, 1024개의 스레드 그룹에서 직면했던 많은 문제들이 줄어들었습니다. 512개의 스레드 그룹 사이즈도 이미 충분히 낫습니다. 각 CU당 5개의 그룹까지가 들어가니깐말이죠. 그러나 좋은 Occupancy를 달성하기 위해, 빡빡한 32개의 VGPR 제한에 맞출 필요는 여전히 존재합니다.(각주 : 스레드 그룹 사이즈를 줄이는 것도 도움이 됬지만, VGPR을 낮추는 것도 여전히 필요하다)
Neighborhood processing(인접 처리)
흔히들 사용되는 (temporal antialiasing, blurring, dilation, and reconstruction와 같은) 포스트 프로세스 필터는 가장 가까운 인접 Fragment의 정보를 요구합니다. 이러한 필터들은 불필요한 메모리 접근을 줄여주는 LDS를 사용함으로서 상당한 비용 감수를 이룰 수 있습니다. 몇몇 경우에는 30%까지도요.
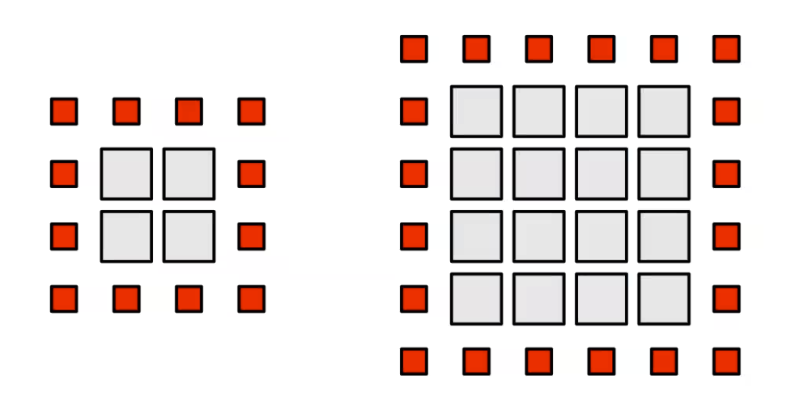
만약 우리가 2D Input을 생각한다면, 각 스레드는 하나의 픽셀을 쉐이딩하게 됩니다. 그리고 우리는 각 스레드가 그것의 초기 값뿐만 아니라, 인접 8개의 픽셀 값들도 읽어야한다는 것을 알 것입니다. 각 인접 픽셀 또한 그 스레드의 초기 값을 요구합니다. 추가적으로, 중앙 값은 각 인접 픽셀의 스레드들에 의해 요구됩니다. 이는 수 많은 불필요한 메모리 읽기로 이어집니다. 일반적인 경우, 각 픽셀은 9개의 서로 다른 스레드들에 의해 읽어질 것입니다. LDS가 없다면, 각 픽셀은 9번 로드되어야 합니다(각 스레드가 한번씩 읽으니깐요)
요구되는 데이터를 LDS로 로드하고, 모든 이후 메모리 로드 동작을 LDS 로드로 대체함으로서, 우리는 글로벌 메모리로의 접근을 상당수 줄일 수 있고 뿐만아니라 잠재적인 캐시 thrashing도 줄일 수 있을 것입니다.
그룹 내에서 공유될 수 있는 데이터가 상당히 많은 경우 LDS는 상당히 효과적입니다. 더 큰 인접 픽셀, 즉 더 큰 그룹 사이즈는 더 많은 데이터가 공유될 수 있게된다는 의미고, 더 많은 불필요한 메모리 읽기를 줄여줄 것입니다.
한 픽셀 옆, 사각형 2d 스레드 그룹을 생각해봅시다. 그 그룹은 그룹에 속한 모든 픽셀을 로드하여야하고 경계선 조건을 충족하기 위해 한 픽셀 경계선을 로드하여야합니다. 길이가 X인 사각형 지역은 X^2만큼의 픽셀 + 4X+4만큼의 경계선에 속한 픽셀들을 필요로합니다. 내부 페이로드(각주 : 데이터 양)는 2차적으로 커지고, 읽지만 쓰지는 않을 경계선 픽셀들은 선형적으로 커집니다.
한 픽셀만큼의 경계선을 가진 8X8 그룹은 64개의 내부 픽셀과 36개의 경계선 픽셀을 포함한다. 이는 총 100개의 메모리 읽기이고 56%의 오버헤드를 요구한다.
16x16 스레드 그룹을 생각해보자. 페이로드는 256개의 픽셀과 68개의 경계선 픽셀을 포함한다. 비록 페이로드 사이즈가 4배 커졌지만, 오버헤드는 오직 68 픽셀, 27%만 커졌다. 그 그룹의 차원을 두 배로 만듬으로서, 우리는 오버헤드를 상당히 줄일 수 있다. 가능한 가장 큰 사이즈 1024 스레드의 경우, 32x32의 인접 픽셀, 132개의 경계선 픽셀 읽기의 오버헤드는 단지 13%의 로드만을 요구한다.
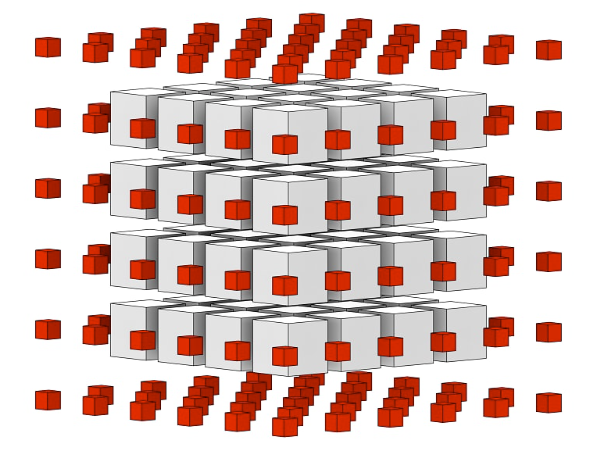
3D 그룹은 경계선 영역보다 그룹 볼륨이 훨씬 빠르게 증가하기 때문에 훨씬 낫다. 작은 4x4x4 그룹에 대해, 페이로드는 64개의 엘리먼트를 포함하는 반면 표면 경계에 있는 6x6x6의 빈 큐브는 216개의 엘리먼트를 요구하고 이는 70%의 오버헤드이다. 그러나, 512개의 내부 픽셀을 가진 8x8x8 그룹과 488개의 인접 픽셀은 48%만의 오버헤드를 요구한다. 작은 스레드 그룹 사이즈에서 인접 오버헤드는 크지만, 큰 스레드 그룹사이즈에는 오버헤드는 줄어든다. 확실히, 큰 스레드 그룹은 그 쓰임새가 있다.
LDS를 통한 멀티 패스
멀티 패스를 요구하는 많은 알고리즘이 있다. 간단히 구현하려면 중간 결과를 글로벌 메모리에 저장하는 것이고 이는 상당한 메모리 대역폭을 소모한다.
때때로 어떠 문제의 각각의 독립적인 파트(섬)는 작고, 중간 결과를 LDS에 저장함으로서 문제를 여러 단계, 패스로 쪼갤 수 있다. 하나의 컴퓨트 쉐이더는 요구되는 모든 단계를 수행하고, 각 스텝 중간에 중간 결과를 LDS에 쓴다. 오직 최종 결과만 글로벌 메모리에 쓴다.
피직스 솔버는 이러한 접근법을 적용하기 좋은 예이다. Gauss-Seidel와 같은 Iterative 기술들은 모든 제약들을 안정화시키기 위해 여러 스텝을 필요로 한다. 그 문제는 여러 섬들로 쪼갤 수 있다. 하나의 연결된 몸의 모든 파티클들은 동일한 스레드 그룹에 배정되고, 독립적으로 처리된다. 이후 패스에서 이전 패스에서 계산된 중간 데이터를 사용함으로서, body간의 상호작용을 다룬다.
VGPR 사용 최적화
큰 스레드 그룹을 가진 쉐이더들은 복잡한 경향이 있다. 32개의 VGPR 목표를 달성하는 것은 어렵다. 아래에서 소개할 것들은 내가 지난 몇 년간 배운 몇 가지 트릭들이다.
Scalar Data
GCN 기기는 한 Wave에서 각 스레드들에 대해 각기 다른 상태를 유지하는 “vector (SIMD) 유닛”과, 한 Wave에 속한 모든 스레드들에 대해 공통된 상태를 가지는 “Scalar Unit”을 둘 다를 가진다. 각 SIMD Wave에 대해, 자신의 SGPR 파일을 가진 하나의 추가적인 scalar 스레드가 동작을 한다. 그 Scalar 레지스터는 전체 Wave에 대해 단일 값을 가진다. 그러므로, SGPR는 64배 낮은 on-chip 저장공간 비용을 가진다.
GCN 쉐이더 컴파일러는 알아서 scalar 로드 명령어를 생성한다. 만약 load 주소가 wave-invariant(즉, 그 wave에 속한 64개의 모든 스레드가 load할 주소가 동일한 경우)하다는 것이 컴파일시 확인되면, 컴파일러는 같은 데이터를 각 wave가 각자 독립적으로 로드하기 보다는, scalar load 명령어를 생성한다. wave-invariant한 데이터에는 대표적으로 상수 버퍼(constant buffers)와 상수 값이 있다. scalar unit이 완전한 정수 명렁어 세트를 가지고 있기 떄문에, wave-invariant한 데이터를 기반으로 한 모든 정수 수학 연산 결과는 wave-invariant하다. 이러한 scalar 명령어들은 vector SIMD 명령어들과 함께 issue되며, 실행 시간 측면에서 대걔는 공짜이다.
컴퓨트 쉐이더 built-in input 값, “SV_GroupID” 또한 wave-invariant하다. 그것이 그룹 특화된 데이터를 scalar 레지스터로 옮기게 해주어 스레드 VGPR 압박을 줄여준다는 점에서 중요하다.
Scalar 로드 명령어는 typed buffer 혹은 텍스처를 지원하지 않는다. 만약 컴파일러가 너의 데이터는 VGPR 대신 SGPR에 로드하기를 원한다면, “ByteAddressBuffer” 혹은 “StructuredBuffer”에서 데이터를 로드하여야 한다. 그룹에 공통되는(각주 : wave-invariant한) 데이터를 저장하는데 typed buffer와 텍스처를 사용하지마라. 만약 너가 2D/3D 데이터 구조체에서 scalar 로드를 수행하기를 원한다면, 너는 커스텀 주소 계산 수학 연산을 사용해야할 것이다. 다행히도 scalar 유니싱 완전한 정수 명령어 세트를 가지고 있기 때문에. 주소 계산 수학 연산은 효과적으로 함께 issue될 것이다.
SGPR을 전부 소진하는 것도 발생할 수 있다, 흔하지는 않지만… SGPR 한도를 초과하는 가장 흔한 방법은 텍스처나, 샘플러를 과도하게 많이 사용하는 것이다. 텍스처 descriptor는 하나 당 8개의 SGPR을 요구하고, 샘플러는 하나 당 4개의 SGPR을 요구한다. D3D11는 여러 텍스처를 하나의 샘플러로 사용하는 것을 허용한다. 대걔, 하나의 샘플러도 충분하다. 버퍼 descriptors는 오직 4개의 SGPR을 요구한다. 버퍼, 텍스처 로드 명령어는 샘플러 없이 사용할 수 있기 때문에, 필터링이 필요하지 않는 경우 사용하면 된다.
예제 : 각 스레드 그룹은 view, projection 행렬과 같이 wave-invariant한 행렬을 가지고 위치를 변환한다. 4개의 typed load 명령어를 사용하여 “Buffer
불필요한 데이터
Homogeneous coordinates는 3D 그래픽에서 흔히들 사용된다. 대부분의 경우, W 값은 0 아니면 1이라는 것을 안다. 그리고 이 경우 W component를 로드하거나 사용하지마라. 그것은 스레드당 하나의 VGPR을 낭비하고, 더 많은 ALU 명령어를 생성하는 동작이니 말이다.
비슷하게 4x4 행렬은 오직 projection을 하는 경우에만 필요하다. 모든 아핀 변환은 4x3 행령을 요구한다. 4x3 행렬은 4x4 행렬보다 4개의 VGPR 혹은 SGPR을 아낄 수 있다.
Bit 패킹
Bit 패킹은 메모리를 아끼는 유용한 방법이다. VGPR은 매우 소중한 메모리이다. VGPR은 매우 빠르지만, 양이 적다. 다행히도, GCN은 빠르고, 하나의 사이클만을 요구하는 bit-field 추출, 삽입 연산을 제공한다. 이러한 연산을 통해, 데이터의 여러 조각을을 하나의 32-bit VGPR에 저장할 수 있다.
예를 들면, 2D 정수 좌표는 16bit+16bit로 패킹될 수 있다. 또한 HLSL는 2개의 16bit floatsms 32bit VGPR로 패킹하거나, 추출할 수 있는 명령어( f16tof32 & f32tof16 )를 가지고 있다.
만약 데이터가 이미 메모리에서 팩킹되어 있다면, 그 데이터를 uint 레지스터나 LDS로 직접 로드하고, 그것을 사용할 때까지 unpack하지 마라.
Booleans
GCN 컴파일러는 Wave의 lane당 한 비트씩 총 64bit의 bool 변수들을 64-bit SGPR에 저장한다. VGPR는 사용하지 않는다. bool을 나타내기 위해 int나 float를 사용하지마라. 만약 사용한다면 이러한 최적화가 적용되지 않을 것이니깐.
만약 SGPR에서 저장할 수 있는 것보다 더 많은 bool을 가지고 있다면, 32개의 bool을 하나의 VGPR에 bit-packing하여 저장하는 것을 고려해바라. GCN은 bit field들을 빠르게 조작하는, 하나의 사이클만을 요구하는 bit-field 추출/삽입 명령어를 가지고 있다. 추가로 bit-field들의 감소, 탐색을 하기 위해 countbits(), firstbithigh() / firstbitlow()를 사용할 수도 있다. 바이너리 접두사 합계(Binary prefix-sum)은 countbits()를 이용해 이전 비트를 마스킹하고, counting함으로서 효과적으로 구현될 수 있다.
Bool은 항상 양수인 floats의 부호 비트에 저장할 수도 있다. abs(), saturate()는 GCN에서는 공짜인 함수이다. 그것들은 그것들을 사용하는 작업과 함께 실행되는 단순한 입력/출력 수정자입니다. 따라서 부호 비트에 저장된 bool을 읽는 것은 공짜입니다. 부호를 회수하기 위해 HLSL sign() 내장 함수를 사용하지 마십시오. 이는 최적이 아닌 컴파일러 출력을 생성합니다. 부호 비트의 값을 결정하기 위해 값이 음수가 아닌지 테스트하는 것이 항상 더 빠릅니다.
분기와 반복(Branches and Loops)
컴파일러는 데이터를 로드하고 사용하는 지점까지의 거리를 최대한 길게 만들려고 노력하는데, 이는 그 중간 명령어들을 통해 메모리 레이턴시를 숨길 수 있기 때문이다. 불행히도 데이터를 로드하고 사용하기 전까지 데이터는 VGPR에 저장되어야 한다.
다이나믹 루프는 VGPR 생명 주기를 줄이는데 사용될 수 있다. 반복 횟수에 의존하는 로드 명령어는 루프 바깥으로 뺼 수 없기 때문에, VGPR 생명 주기는 반복문의 내로 갇히게 된다.(각주 : 다이나믹 루프를 사용함으로서 반복 횟수에 의존하는 로드 명령어를 반복문 안에 쓰도록 컴파일러에게 강제함으로서 VGPR 사용을 줄임.)
다이나믹 루프를 하도록 강제하기 위해 HLSL 쉐이더 코드에 [loop] 어트리뷰트를 사용하라. 불행히도 [loop]를 사용한 경우에도, 반복 횟수가 컴파일 타임에 결정된 경우 쉐이더 컴파일러는 반복문을 unroll할 것이다. (각주 : unroll, 다이나믹 루프에 대해 잘 모른다면 이 글을 참고하길 바란다.)
16bit 레지스터
GCN3는 16bit 레지스터 지원을 도입하였다. 베가는 16bit 연산을 두배 빠르게 수행함으로서 이를 확장했다. 정수, 부동소수점 둘 다 지원된다. 두 개의 16bit 레지스터는 하나의 VGPR로 패킹될 것이다. 32bit의 full 정밀도가 필요하지 않는 경우 VGPR을 아끼는 가장 쉬운 방법이다. 16bit 정수형은 2D/3D 주소 연산에 적합하다(리소스 로드/저장, LDS 배열). 16bit 부동 소수점은 포스트 프로세싱 필터 처리에 유용한데, 특히 LDR이나 포스트 tonemapped 데이터를 다룰 때 유용하다.
LDS
같은 그룹에 속한 여러 스레드들이 동일한 데이터를 로드할 때, 너는 그 데이터를 LDS에 로드하는 것을 고려해야한다. 이는 명령어 카운트와 VGPR 개수 감소를 크게 가져올 것이다. 또한 LDS는 당장 필요하지 않는 레지스터 데이터를 저장하는데 사용될 수도 있다. 예를 들면, 쉐이더 초반부에 어떤 데이터를 로드하고 사용한 후, 쉐이더의 마지막쯤에 그 데이터를 다시 사용한다고 생각해보자. 불행히도 쉐이더의 중간 지점쯤에서 VGPR 사용은 최고점을 찍을 것이다. 이를 방지하기 위해, 쉐이더 초반부에 로드하고 사용한 후 VGPR에 저장하지 말고, LDS에 임시로 저장해두었다가 이를 필요할 때 다시 로드해보자. 결과적으로 VGPR 최고점에서의 VGPR 사용을 줄일 수 있게 된다.